Problem
When applying computation on a column in Pandas on PySpark Dataframe, the execution does not happen in parallel.
Example
In the following code, a Pandas library is imported from Pyspark and a Pyspark Pandas DF named df is defined. A function temp_function is also included, to apply to the 'col3' column using the apply method. The function also includes a type hint.
%python
# This code runs on driver
import time
from pyspark import pandas as ps
import numpy as np
df2 = ps.DataFrame(np.random.choice([1,2,3], size=(3,3))).rename(columns={0: 'col1', 1: 'col2', 2:'col3'})
print(type(df2))
def temp_function(x) -> int:
print("Hello")
time.sleep(5)
print("Func_end")
return x
df2['col3'] = df2['col1'].apply(lambda x: temp_function(x))
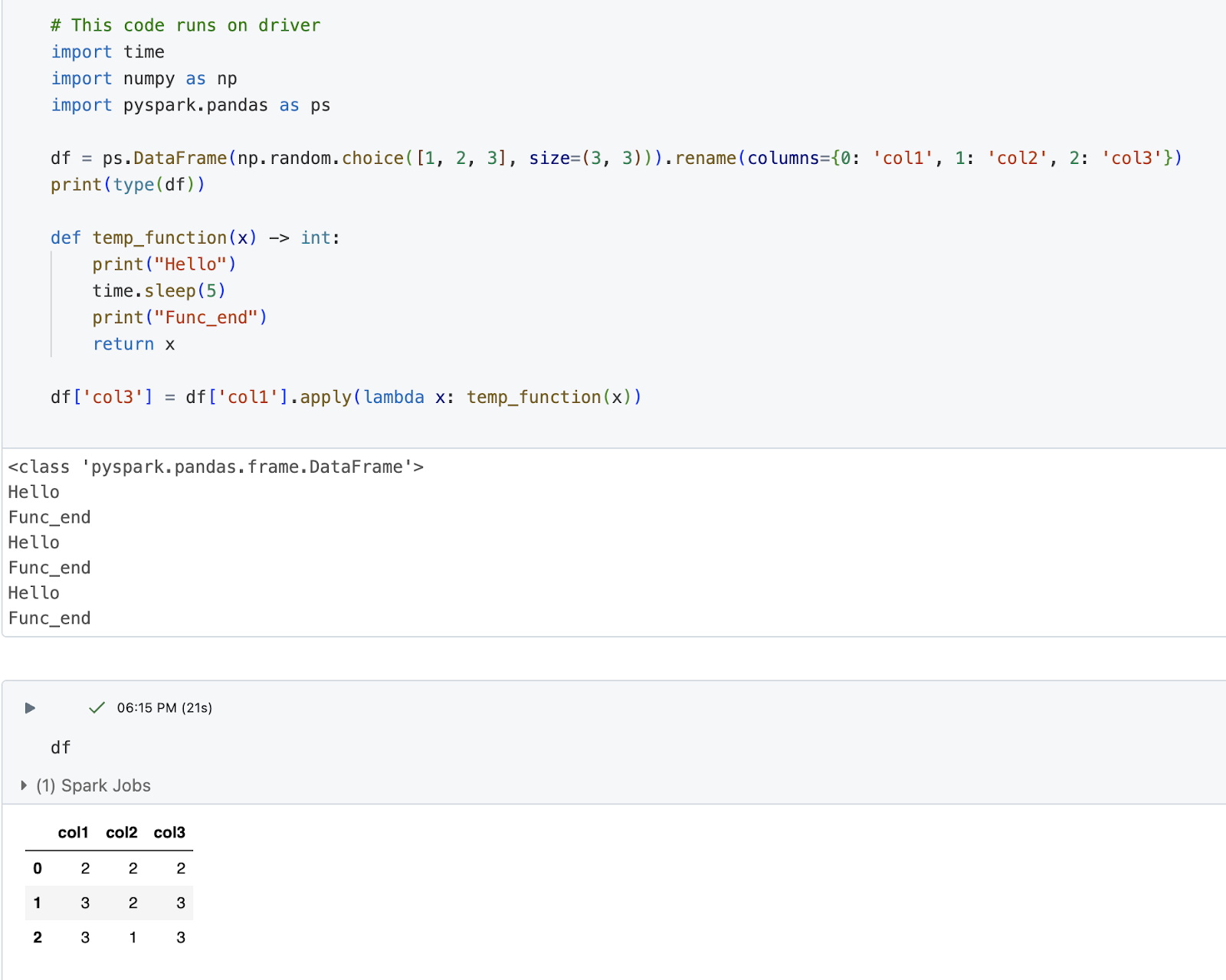
However, this code does not achieve parallel execution as expected. Instead, all operations are confined to the driver.
In the following image, all print statements from temp_function appear directly in the console, rather than in the executor logs. Moreover, the execution is eager, with an Apache Spark job being triggered twice: first when the function is executed and again when the DataFrame is printed.
Cause
The lack of parallel execution in the code stems from the use of the apply method with a Python lambda function, which inherently does not have a return type. Although temp_function is defined with a type hint, the lambda wrapper used in the apply method does not relay this information to PySpark's execution engine.
Consequently, PySpark does not interpret or distribute the execution across the cluster. Instead, it operates only on the driver node, treating the function as a Python function rather than a distributed operation, leading to the eager and non-parallel execution observed.
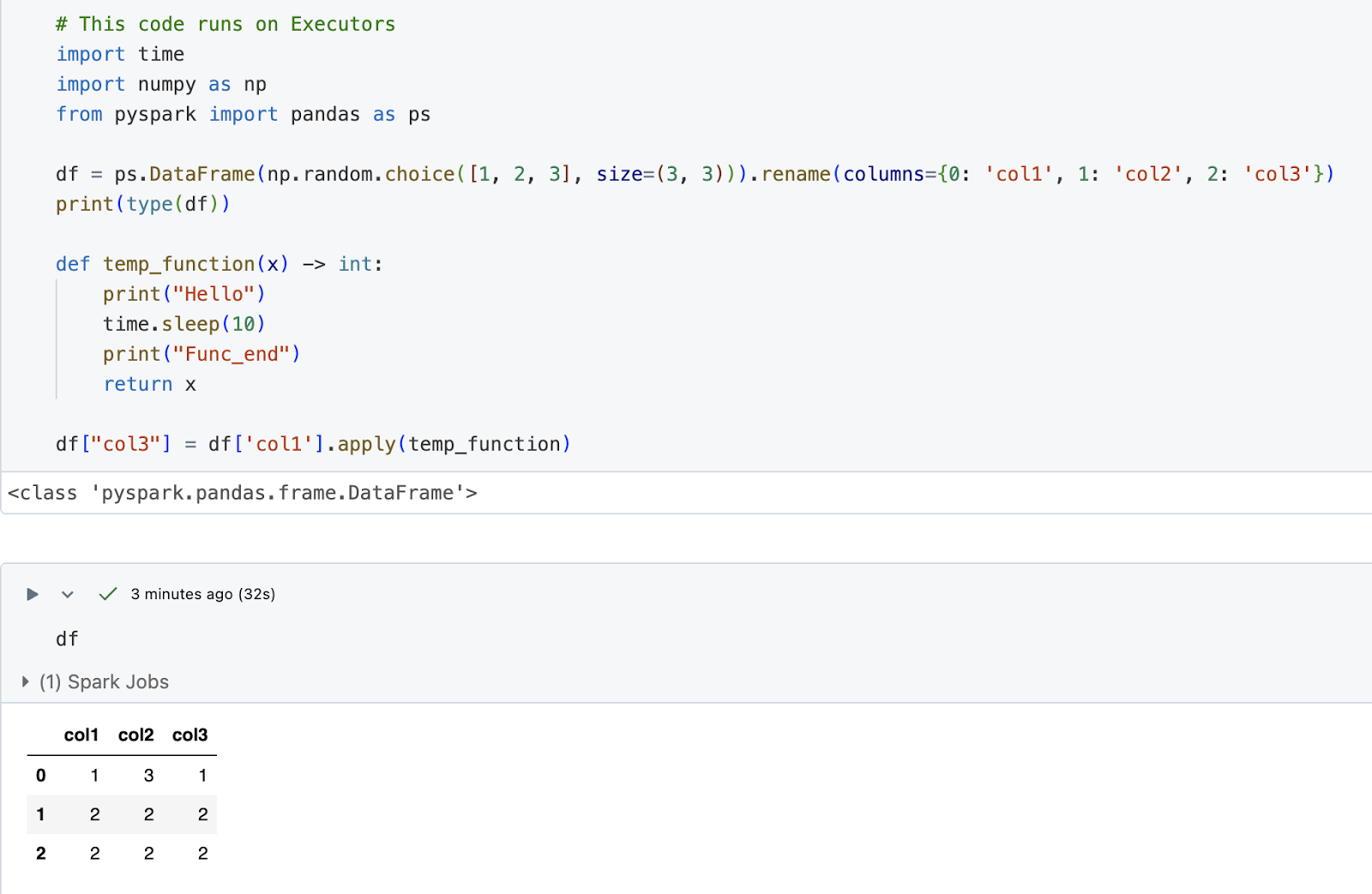
Solution
To ensure parallel execution of operations on a PySpark DataFrame, directly use the apply function from pyspark.pandas without wrapping it in a lambda function.
This approach uses PySpark's capability to distribute tasks across the cluster's executors. By specifying the return type directly in the function definition (temp_function), the return type is read and not inferred, which reduces the execution overhead.
import time
import numpy as np
from pyspark import pandas as ps
df = ps.DataFrame(np.random.choice([1, 2, 3], size=(3, 3))).rename(columns={0: 'col1', 1: 'col2', 2: 'col3'})
print(type(df))
def temp_function(x) -> int:
print("Hello")
time.sleep(10)
print("Func_end")
return x
df['col3'] = df['col1'].apply(temp_function)
In the following image, the print statements within temp_function are now logged in the executor logs instead of the console, confirming the distributed nature of the task execution.